Vercel caveats for automation & scraping
Oct 1, 2022
Ever faced the daunting limitations of distributed processes and web scraping in your projects? You're not alone.
This article describes how I tackled some of the limitations I encountered developing a personal project based on distributed processes and web scraping.
Why Vercel?
Vercel is a “platform for frontend frameworks and static sites, built to integrate with your headless content, commerce, or database”, it’s highly tailored towards NextJS, and vice versa. The team develops and maintains both the framework and the platform.
In summary, NextJS boasts a strong community and robust software perfect for single-page applications.
The goal
What was my goal, you ask? I embarked on crafting a simple web application designed to dynamically display content scraped from various websites. Requirements were pretty basic and tasks were not demanding in terms of resources.
My app consisted of a frontend based on NextJS, and a backend bootstrapped with Supabase. In principle, that should’ve covered all the requirements. The only rare scenario or edge case was: (1) regularly crawling some content, and (2) updating the backend. Simple huh? 🤔
I created a couple of processes that use puppeteer, cheerio, and chrome-aws-lambda¹. To keep things simple, I used this amazing website Next.js Scraper Playground, and built over the files it generates.
It was not long before I had a running version where I could click a refresh button and that would crawl the required pages, store the information in PostgreSQL (hosted by Supabase), and show the information in my frontend.
Sky 50MB is the limit
AWS Lambda functions in Vercel have a limit of 50MB compressed or 250MB uncompressed. The catastrophic message looks more or less like this (disguised as a Warning) as you might have spotted.
Warning Max serverless function size of 50 MB compressed or 250 MB uncompressed reached
This means, you cannot have chrome-aws-lambda imported anywhere in your lambda functions as that will increase the size by ~50MB. Depending on the version you are using you can bring that just below 50MB. But that’s not useful since the app will end up taking some space, an you are basically limiting your options right from the start
Some of the unsuccessful attempts to resolve the problem included (but where not limited to):
- Looking for ways to reduce the size of the packages
- Using puppeteer’s built-in chromium
- Using older packages of chrome-aws-lambda
- Using forked versions of chrome-aws-lambda (@sparticuz/chromium)
One solution
I finally found a solution when I stumbled upon found after a thorough research Browserless. Of course, in this x-less era. The service provides a chromium hosted service for broswerless automation. It’s free to test, and was inexpensive for my use case, according to my first calculations.
Plugin in Browserless was painless. And just after uploading the code…
Sky 10 seconds is the limit
The crawling logic I had implemented was structured in a series of chained procedures. Simply put, I first crawled one or more index pages that contained a series of URLs, and immediately after, I would crawl each of the pages to which those URLs re-directed.
The main point here is the fact that the code was already written and working. I could’ve never imagined such limitation, so re-writing the code was not an option, partly because it required a custom server anyways. And the whole reason to go with Vercel is just not having to deal with Infrastructure.
The solution: The serverless advantage
Despite the fact that microservices are starting to get detractors here and there, and others moving away from the cloud, it’s the golden 🏆 era for both of them, in my humble opinion.
So I figured there must be something out there that
- does not require a server set up
- does not require using a new technology (stack is already big enough to start with)
- helps me solve my Q problem
While I did consider BullMQ and found lots of inspiration in this article which explains how the folks at Hyperjump Separated concerns using Redis and Bull, that still meant I had to use redis myself, and actually implement the Q.
So I finally decided to go with QStash, a new service, that promissed messaging and queuing made dead simple. And they did live up to the promise so far.
While QStash has an SDK, I just had a few calls to make, they would handle the rest. The only problem I found was they don’t allow redirection to localhost, but nothing you can’t solve with NROK.
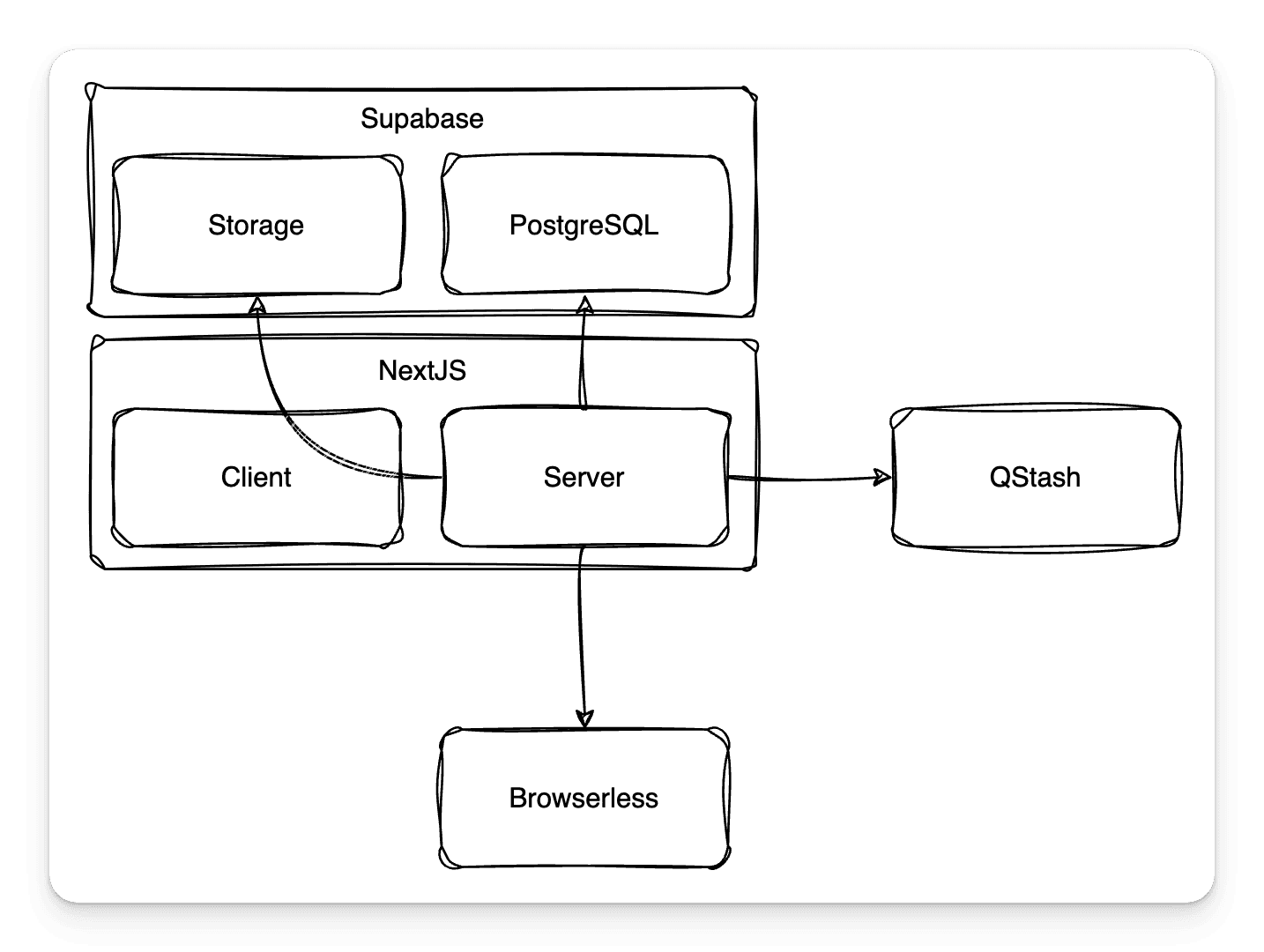
The architecture
Summarizing, I had to workaround the fact that
- I only have 10 seconds to execute any given lambda function
- I can only use <50MB total library space
- Work needs to be done by batches, ideally in parallel
The final picture included the following
- My server (NextJS Node code) which would manage all requests and channel them appropriately
- QStash which manages a Q of jobs, when told to
- Browserless executing async scraping tasks when told to
- My server again routing all the information to persistent storage
Conclusion: A Journey of Discovery and Innovation
In conclusion, the development of my web application, despite its initial hurdles, stands as a testament to the power of persistence and innovative thinking. By leveraging tools like Browserless and adapting to the limitations of serverless functions, I was able to create a solution that met my needs and expanded my understanding of what's possible in the realm of web development.
I encourage you to share your own experiences with distributed processes, scrapping, or serverless architectures. Have you encountered similar challenges? What solutions have you found? Let's create a space for knowledge exchange and mutual growth. Feel free to comment below or suggest related readings that have inspired you on this journey.
UPDATE 2023-09-30 : Over time, I found out that some of the problems I was having with the built in version of chromium in puppeteer were due to yarn. Migrating to NPM solved those, and in turn started including chromium in my packages. I will eventually test embedding this and removing Browserless all in all.
UPDATE II 2023-12-12: I eventlually removed Browserless cloud from the stack and deployed my own version on a server. Embedding does not make sense for a service like this and it’s much more efficient to have the container do the heavy lifting.
- Puppeteer comes with a built in chromium that should work. However I never managed to get it working on the serverless environment. For the sake of simplicity won’t cover that path, which I ultimately had to move away from.